
حوضه های رودخانه شانون و بخش ها
چکیده
برنامه ریزی، مدیریت و پیش بینی نیازها و استفاده از آب باید قبل از تجزیه و تحلیل تغییرات درازمدت برای پارامترهای مرتبط با آن، به منظور بهبود روند توسعه سناریوهای جدید، برای منابع آب سطحی یا آب های زیرزمینی صورت پذیرد. هدف از این مقاله ارائه یک روش مناسب برای پیش بینی طولانی مدت جریان آب و پارامترهای آب رودخانه "شانون" در ایرلند طی یک دوره 30 ساله از سال های 1983 تا 2013 و از طریق چارچوبی است که از سه مرحله تشکیل شده است: مقیاس گسترده تجزیه و تحلیل شهری، داده های تلفیقی، و مرحله حدود علم تحلیل داده ها که تمرکز اصلی مقاله است که با استفاده از یک مدل یادگیری ماشین بر اساس شبکه های عصبی پیچیده عمیق (DeepCNNs) بکار برده می شود. مدل یادگیری عمیق پیشنهاد شده را در سه ایستگاه مختلف آب در رودخانه شانون تست می کنیم و نشان می دهیم که چهار مدل پیش بینی سری زمانی شناخته شده است. ما در نهایت مدل پیشنهادی شبیه سازی جریان آب و سطح آب پیش بینی شده از سال های 2013 تا 2080 را نمایش می دهیم. راه حل پیشنهادی ما می تواند برای مقامات علوم آب بسیار مفید باشد. بخصوص برای برنامه ریزی بهتر تخصیص منابع آب در میان کاربران رقابتی مانند کشاورزان. علاوه بر این، می توان آن را برای تطابق ناهنجاری ها با تنظیم و مقایسه آستانه ها با جریان آب پیش بینی شده و سطح آب مورد استفاده قرار داد.
مقدمه
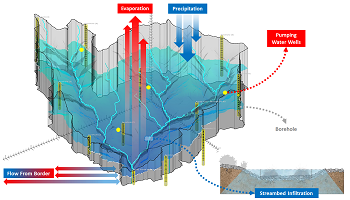
شبیه سازی و پیش بینی در گام های زمانی روزانه برای پارامترهای هیدرولوژیکی به خصوص جریان آب روزانه (streamflow) و سطح آب با مرتبه دقت بالا در مقیاس حوضه، نقش کلیدی در روند مدیریت سیستم های منابع آب دارد. مدل های قابل اطمینان و پیش بینی ها می تواند به شدت به عنوان یک ابزار توسط مقامات آب در تخصیص منابع آبی در میان کاربران رقابتی مانند بخش کشاورزای، نیروگاه ها و... مورد استفاده قرار گیرد. استخراج ویژگی های حوضه از جنبه های مهم در هر فرآیند پیش بینی و مدل سازی هیدرولوژیکی است. عملکرد روش های مدل سازی و طرح ریزی برای ایستگاه هیدرومتری با توجه به منطقه آب و هوایی حوضه آبریز آن و ویژگی های حوضه متفاوت است. کاران و همکاران [11] بیان می کنند که روش هایی که برای مدل سازی جریان آب در مناطق پر آب اثبات شده اند ممکن است برای زیرساخت های ناحیه خشک کارایی نداشته باشند، جایی که کمبود آب یک واقعیت است به دلیل ماهیت متناوب جریان ها. خصوصیات آب و هوایی ممکن است به شدت بر عملکرد روش های مختلف پیش بینی در حوزه های مختلف تاثیر بگذارد و این مبحث تحقیقی، هنوز نیاز به مطالعات بیشتری دارد. درک جریان رودخانه و پویایی سطح آب بسیار مهم است، که توسط مکانیزم های مختلف فیزیکی در طیف گسترده ای از مقیاس های زمانی و مکانی توصیف می شود. شبیه سازی این مکانیسم ها و روابط می تواند با مدل های فیزیکی، مفهومی و یا داده ها اجرا شود. با این حال، مدل های فیزیکی و مفهومی تنها راه های فعلی برای ارائه تفسیر های فیزیکی و تصاویر به فرایندهای مقیاس ساحلی هستند؛ آنها در حل مسائل برای پیش بینی مقیاس زمانی با وضوح بالا مورد انتقادهایی قرار گرفته اند، علاوه بر این نیاز به انواع مختلفی از مجموعه داده ها هست، که معمولا برای به دست آوردن آنها دسترسی ها بسیار دشوار است. به طور کلی، مدل های فیزیکی و مفهومی برای اجرای بسیار دشوار هستند و با وضوح بیشتر آنها، اطلاعات بیشتری که نیاز دارند، منجر به مدل های پیچیده پارامتریزه تر می گردد.
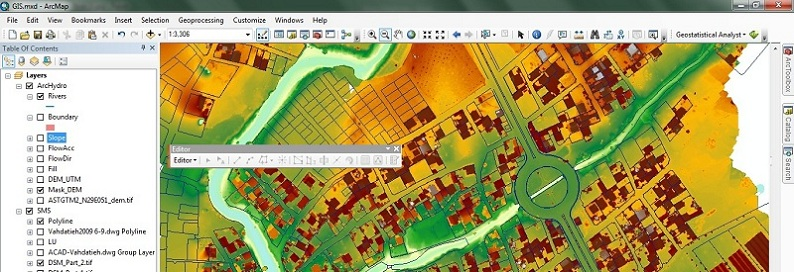
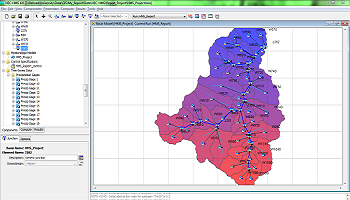
در این مقاله، یک چارچوب مدیریت آب معرفی شده است که هدف آن ارائه بینش درست نسبت به نحوه تخصیص بهتر منابع آب با ارائه یک مدل پیش بینی دقیق و بر اساس شبکه های عصبی پیچیده عمیق (که به عنوان DeepCNNs در بقیه مقاله نامیده می شود) است. این مدل برای پیش بینی جریان آب و سطح آب برای رودخانه شانون در ایرلند، طولانی ترین رودخانه در ایرلند در 360.5 کیلومتر ارائه می شود. این رود، حوضه شانون را تخلیه می کند که مساحت آن بالغ بر 16، 865 کیلومتر مربع، یک پنجم از منطقه ایرلند است. شکل. 1 بخش های حوضه و رودخانه شانون را در سراسر ایرلند نشان می دهد. این مقاله اولین برای بار است که به بررسی و اثربخشی مدل های یادگیری عمیق در حوزه هیدرولوژی برای پیش بینی های بلند مدت با استفاده از مدل شبکه های عمیق یادگیری و مقایسه عملکرد آن و نشان دادن آن از انجام دیگر مدل های پیش بینی مدل سری زمانی پرداخته است. ما این مقاله را به صورت زیر تنظیم می کنیم: بخش 3 چارچوب پیشنهادی ما را برای مدیریت آب معرفی می کند. بخش 4 ارائه معماری پیشنهاد شده از شبکه های عصبی کانولوشن عمیق است. بخش 5 آزمایشات و نتایج ما را نشان می دهد. سرانجام، مقاله را در بخش 6 به پایان می رسانیم.
کار مربوطه
شبکه های عصبی مصنوعی (ANNs) در هیدرولوژی در بسیاری از برنامه های کاربردی مانند جریان آب (streamflow)، ارزیابی کیفیت و پیش بینی بار رسوب معلق استفاده شده است. اولین استفاده برای ANN در هیدرولوژی که پیشتر معرفی شد، روش مناسب برای فرآیند پیش بینی در کاربرد هیدرولوژیکی را پیدا می کند. پس از آن ANN در بسیاری از برنامه های کاربردی هیدرولوژیکی برای تأیید سودمندی و مدل سازی پارامترهای مختلف هیدرولوژیکی برای streamflow استفاده شده است. به نظر می رسد مدل های ANN چند لایه (MLP)، بیشترین استفاده از الگوریتمهای ANN هستند که با الگوریتم بازگشتی بهینه سازی شده اند، این مدل ها پیش بینی های کوتاه مدت هیدرولوژیکی را بهبود می بخشد. مثال هایی از برنامه های اخیر قابل توجه منتشر شده برای استفاده از ANN در هیدرولوژی عبارتند از: [2] [12]. ماشین های بردار پشتیبانی (SVM) اخیرا با برنامه های کاربردی هیدرولوژی سازگار شده اند که در ابتدا در 2006 توسط خان و کولیبالی در [13] استفاده شد، در نتایج این مطالعه آنها می گویند که مدل SVR مدل های MLP را در پیش بینی های سطح آب در مقیاس 3-12 ماهه انجام می دهد و سپس استفاده از SVM در هیدرولوژی، در استفاده از ارقام سیل در مطالعات بسیاری مطرح شده است. پیش بینی جریان طوفان، مدل سازی جریان آبراهه و حتی برآورد تبخیر تعرق روزانه.
توان محدود برای پردازش داده های غیر ثابت، بزرگترین نگرانی از تکنیک های یادگیری ماشین های اعمال شده به دامنه هیدرولوژی است که منجر به استفاده اخیر از مدل های ترکیبی می شود، در حالیکه داده های ورودی برای اولین بار برای ویژگی های غیر ثابت پیش پردازش شه و سپس اجرا می شوند از طریق مدل های یادگیری ماشین پس پردازش؛ که در واقع برای مقابله با مسائل غیر خطی این روش صورت می گیرد. تحولات موجک همراه با مدل های یادگیری ماشین ثابت شده است که توانمند به ارائه بسیار دقیق و قابل اعتماد پیش بینی های کوتاه مدت است. به عنوان مدل ترکیبی محبوب ترین مورد؛ انتقال موجک و شبکه ی عصبی مصنوعی (WANN) است. کیم و والیپه (2003) [14] یکی از اولین کاربرد هیدرولوژیکی مدل WANN که در منطقه پیش بینی خشکسالی در حوضه رودخانه کانچوس واقع در مکزیک قرار دارد را انجام دادند و سپس بسیاری از مطالعات منتشر شده، استفاده از WANN در پیش بینی جریان و بسیاری از زمینه های تحقیقاتی در مدل سازی و پیش بینی هیدرولوژیکی را تحقیق نمودند. به طور کلی، تمام مطالعاتی که بین ANN و WANN مقایسه می شود، نتیجه گیری می کنند که مدل های WANN تنها و به صورت منفرد از ANN استفاده می کنند [3]. علاوه بر این، تبدیل موجک همراه با (SVM/SVR (WSVM/WSVR پیشنهاد شده است که در برنامه های کاربردی هیدرولوژی استفاده شود. به همین علت، پژوهشی بسیار کوچک در مورد استفاده از این مدل هیبرید برای پیش بینی جریان آبراهه وجود دارد و هیچ برنامه پیش بینی سطح آب وجود ندارد.
کاران و همکاران [11] مقایسه استفاده از چهار مدل مختلف، شبکه های عصبی مصنوعی (ANNs)، رگرسیون بردار پشتیبانی (SVR)، موجک-ANN و wavelet-SVR برای یک ایستگاه تک در هر حوضه آبخیز دریای مدیترانه، اقیانوسی و حوضه Hemiboreal را انجام دادند که نتایج نشان می دهد که مدل های مبتنی بر SVR بهترین عملکرد را دارند. کیسی و همکاران [16] مدل های WSVR را با روش های مختلفی برای مدل جریان آبراهه ماهانه مورد استفاده قرار داده اند و دریافتند که مدل های WSVR از SVR مستقل استفاده می کنند. از کارهای قبلی، ما نتیجه گرفتیم که مدل یادگیری ماشین پیشین (ANNs ،SVM ها، WANNS، و WSVM ها) بیشتر مورد مطالعه بوده و شناخته شده در زمینه هیدرولوژی هستند. از این رو، در این مقاله چهار خط پایه را با استفاده از مدل های قبلی ذکر می کنیم که برای مقایسه پیشنهادی شبکه های عصبی پیچیده عمیق پیشنهاد شده ما در سه ایستگاه مختلف آب بندی مناسب است. به همین علت، این مقاله اولین روش تطبیق روش عمیق یادگیری در حوزه هیدرولوژی است و دقت بهتری را در سه ایستگاه آبی نسبت به مدل های مدرن استفاده شده در برنامه های هیدرولوژی نشان می دهد.
چارچوب مدیریت آب
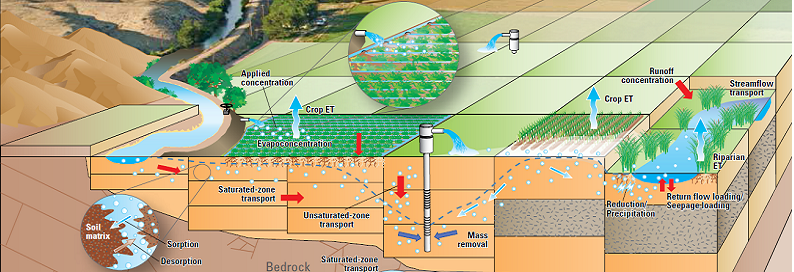
در این بخش، ما سه مرحله برای چارچوب پیشنهاد شده برای پیش بینی جریان آب و سطح آب را از طریق تجزیه و تحلیل چند مرحله خلاصه می کنیم. (الف) تجزیه و تحلیل داده ها در سطح گسترده ای از شهر: این مرحله به طور عمده از دو مرحله تشکیل می شود، مرحله اول استفاده از مدل تعادل آب توزیع مکانی فضایی است و یکپارچه سازی تغییرات آب و هوایی و کاربری زمین است. این مرحله از طیف گسترده ای از پارامترهای ورودی و شبکه ها از جمله متغیرهای فصلی محیطی و تغییرات آن، کاربری زمین و پارامترهای فصلی آن و تغییرات آینده، عمق فصلی آب زیرزمینی، ویژگی های خاک، توپوگرافی و شیب استفاده می کند. خروجی این مرحله چندین پارامتر شامل رواناب، تغذیه، رهگیری، تبخیر تعرق، تبخیر خاک، انتقال از جمله عدم اطمینان و یا خطا در تعادل آب است. ما از این مرحله به عنوان یک ویژگی استخراج شده برای ذخیره سازی داده ها استفاده می کنیم (برای توصیف مدل مورد استفاده به [6] مراجعه کنید). در مرحله دوم، ما داده ها را برای temp-max و temp-min از Met Eireann از سال 1983 تا 2013 خدمات هواشناسی ملی در ایرلند، جمع آوری کردیم. ما همچنان دمای های آینده را از 2013 تا 2080 را با استفاده از مدل مقیاس آماری پایین که در [7] شرح داده شده است شبیه سازی کردیم. (ب) فیوژن داده: در این فاز، ما روش فیوژ مبتنی بر مرحله [22] را دنبال می کنیم که در آن، ویژگی های استخراج شده از مرحله قبل با دو خروج مشاهده شده برای جریان آب و سطح آب از 1983 تا 2013 است.
علاوه بر این، ما داده ها را به صورت نرمال و مقیاس بندی می کنیم و آن را در یک ذخیره سازی داده ذخیره می کنیم تا برای مرحله بعدی پردازش شود. (ج) تجزیه و تحلیل داده های دانش دامنه: این مرحله تمرکز اصلی ما برای مقاله است که در آن ما ویژگی های ذخیره شده در بخش ذخیره سازی داده ها را مصرف می کنیم و مدل پیشنهادی ما همراه با مدل های پایه برای پیش بینی جریان آب و سطح آب در سراسر سه ایستگاه آب مختلف بکار گرفته می شود.
چارچوب مدیریت آب
شبکه های عمیق عصبی کانولوشن
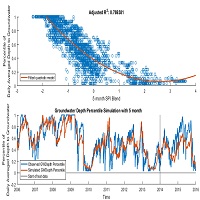
برای طراحی یک مدل پیش بینی مؤثر جهت پیش بینی جریان آب و میزان سطح آب در چندین سال، ما نیاز به استفاده از ماهیت سری زمانی داده ها داشتیم. به طور مستقیم، تجزیه و تحلیل داده ها در طول یک فاصله زمانی کافی وسیع و نه تنها شامل آخرین خواندن به طور بالقوه منجر به اطلاعات بیشتری برای جریان آب و سطح آب می شود. رویکرد اول این است که ما نمونه های داده های مختلف را با هم تلفیق می کنیم و آنها را به یک مدل یادگیری ماشین می چسبانیم، این همان چیزی است که ما در مدل های پایه انجام دادیم که عملکرد را افزایش می دهد. برای دستیابی به پیشرفت های بیشتر، ما از کفایت شبکه های عصبی کانولوشن برای چنین نوع داده ها استفاده می کنیم [18]. ما معماری زیر را پیشنهاد می کنیم، هر نمونه ورودی شامل 10 قرائت متوالی است که با هم مرتبط می شوند (10 مورد در مجموعه داده ها). هر یک از سه ویژگی ورودی (Temp-max، Temp-min و Run-off) به شبکه در یک کانال جداگانه ارسال می شود. مجموعه داده حاصل یک تانسور از ابعاد 𝑁 × 𝑇 × 𝐷 است، که 𝑁 تعداد نقاط داده است (تعداد کل رکورها منهای تعداد خواندن مختصات). 𝑇 طول رشته های تلفیقی حوادث است و 𝐷 تعداد ویژگی های جمع آوری شده است. هر یک از سوابق تانسور نتیجه ای از ابعاد 1 × 𝑇 × 𝐷 توسط یک ستون از لایه های کانولوشن پردازش شده است که همانطور که در شکل نشان داده شده است، پردازش می شود.
اولین لایه کانولا از مجموعه ای از فیلترهای کانول سه کانالی استفاده می کند. ما از مکانیزم های جمع آوری استفاده نمی کنیم، زیرا ابعاد داده ها نسبتا کم است. علاوه بر این، برای نگهداری ورودی، از پد صفر استفاده شد. ابعاد داده هر یک از این فیلترها یک بردار با طول 10 را فراهم می کند، هر یک از عناصر آن به تبدیل غیر خطی با استفاده از ReLu در منبع [19] به عنوان یک تابع انتقال داده می شود. خروجی های نتیجه بیشتر توسط لایه های مشابه دیگر از لایه های کانولوشن پردازش می شود، زیرا کانال های بسیاری مانند کانولاسیون فیلتر در لایه قبلی است. با توجه به یک رکورد ورودی 𝑥، می توانیم ورودی های خروجی توسط فیلتر 𝑓 لایه کانوول 𝑙 را در موقعیت 𝑖 نشان دهیم، همانطور که در معادله 1 نشان داده شده است. در نهایت، آخرین لایه کنوولانس مسطح شده و از طریق یک لایه کامل متصل به feedforward مورد پردازش قرار می گیرد.
معماری شبکه عصبی مصنوعی پیشنهاد شده (DeepCNNs).
آزمایش
در این بخش، ابتدا مجموعه داده های مورد استفاده در آزمایش های ما را شرح می دهیم، سپس ما یک مرور کلی از مدل های پایه استفاده شده را ارائه می دهیم، و در نهایت نتایج در مورد یافته های کلیدی و مشاهدات نشان داد خواهد شد.
مجموعه داده
به دنبال روش های شرح داده شده در شکل 2، مجموعه داده های حاصل شده در ذخیره سازی داده ها شامل پنج پارامتر می شود، حداکثر دما، خدأقل دما، رواناب، جریان آب و سطح آب که در آن سه مورد اول نشان دهنده ویژگی های مدل های آموزش دیده بوده؛ در حالی که دو مورد بعدی نشان دهنده خروجی مدل ها است. پارامترهای مورد استفاده می توانند به صورت زیر تعریف شوند:
- max-temp، min-temp: این بالاترین و کمترین درجه حرارت ثبت شده به صورت ° C در هر روز در مجموعه داده است.
- رواناب: رواناب به عنوان بخشی از چرخه آب شناخته می شود که بخشی از آن بر روی زمین به عنوان آب سطحی به جای جذب در آب های زیرزمینی و یا تبخیر جریان داشته و در واحد is اندازه گیری می شود.
- جریان آب: جریان آب (streamflow) حجم آبی است که از طریق یک نقطه خاص در یک جریان طی یک دوره معین (یک روز در اینجا) حرکت می کند و در واحد is به صورت متر مکعب در روز اندازه گیری می شود.
- سطح آب: این پارامتر نشان دهنده حداکثر ارتفاع آب در رودخانه در طول روز بوده و در واحد متر اندازه گیری می شود.
پارامترهای قبلی در مجموعه داده برای 30 سال (از 1983 تا 2013) در 11392 نمونه که هر نمونه یک روز را نشان می دهند، خواهند بود. مجموعه داده ها مربوط به سه ایستگاه هیدرومتری آب می شود به نام های، Inny، ower-shannon، و suck.
مسیر کار
در این بخش ما مدل های پایه ای که برای ارزیابی عملکرد شبکه پیشنهادی کانولوشن عمیق ساخته شده اند را توصیف می کنیم. ما دو الگوریتم یادگیری رایج معمول را انتخاب می کنیم که قبلا موفقیت آنها در شبکه های عصبی مصنوعی (ANNs) در منبع [8] و ماشین های بردار پشتیبان (SVM) در منبع [4] مشخص شده است.. علاوه بر این، ما دو مدل تبدیل موجک را انتخاب می کنیم که نتایج پایدار و به ویژه برای پیش بینی های سری زمانی، Wavelet-ANNs یا (WANNs) و Wavelet-SVM یا (WSVMs) را نشان می دهد.
- ANNs: ما یک شبکه عصبی feed-forward سه لایه با استفاده از الگوریتم backpropagation را توسعه دادیم. الگوریتم RapidMinder خودکار پیشنهاد شده در [17] برای بهینه سازی تعداد نورون ها در لایه پنهان با تنظیم تعداد epochs برابر 500، سرعت یادگیری برابر 0.1 و سرعت حرکت تا 0.1 نیز مورد استفاده قرار گرفت.
- SVMs: ما SVM با هسته نقطه غیر خطی توسعه دادیم که نیاز به دو پارامتر دارد که توسط کاربر تنظیم می شود یعنی cost یا (𝐶) و epsilon یا (ε). ما 𝐶 را برابر 0.0001 و ε برابر 0.001 تنظیم می کنیم. ترکیب انتخاب شده با دقت تنظیم شده است که می تواند از طریق یک فرآیند آزمایش و خطا برای بهینه سازی بیشتر در حالت محلی برای پارامترهای مدل بدست آید.
ما از تبدیل های موجک دیجیتال (DWTs) استفاده کردیم تا سری های زمانی اصلی را به یک نمایش فرکانس زمان در مقیاس های مختلف (سری های فرعی موجک) تجزیه کنیم. در این نوع از خطوط اولیه، سطح تجزیه به 3، دو سطح جزئیات و یک سطح تقریبی را تعیین می کنیم. سیگنال ها با استفاده از الگوریتم  در منبع [5] در ارتباط با db1 غیر متقارن عنوان عملکرد مادر تجزیه شدند. سه مجموعه از سری های فرعی موجک، از جمله مولفه فرکانس کم (تقریب) ایجاد شده که روند سیگنال را باز می کند و دو مجموعه اجزای فرکانس بالا (جزئیات). سیگنال اصلی همیشه با جمع کردن جزئیات با صاف ترین تقریب سیگنال بازسازی می شود. تمام سری های زمانی ورودی از طریق تبدیل موجک طراحی شده و در زیر مجموعه داده های حاصل از مدل های زیر استفاده شده است:
- WANNs: سری زمانی تجزیه شده به یک روش ANN برای پیش بینی جریان آب و میزان سطح آب برای یک روز پیش می رود. مدل WANNs از تبدیل موجک گسسته برای غلبه بر مشکلات مرتبط با مدل ANN معمولی استفاده می کند، زیرا تغییر شکل موجک برای غلبه بر خواص غیر ثابت از سریهای زمان شناخته شده است.
- WSVMs: WSVR همانند مدل WANN ساخته شده است.
ترجمه: سایت بیسین
پروژه تخصصی در لینکدین











 در منابع آب
در منابع آب


























نظرات (۰)