



پیش بینی سری زمانی در پایتون - قسمت 4
مدل های چند مرحله ای
هر دو مدل تک خروجی و چند خروجی در بخشهای قبلی، پیش بینی های مرحله یک زمانه را برای 1 ساعت در آینده انجام دادند.
این بخش به چگونگی گسترش این مدل ها برای پیش بینی گام های زمانی متعدد می پردازد.
در یک پیش بینی چند مرحله ای، مدل باید یاد بگیرد که طیف وسیعی از مقادیر آینده را پیش بینی کند. بنابراین، برخلاف یک مدل تک مرحله ای، که فقط یک نقطه آینده واحد پیش بینی می شود، یک مدل چند مرحله ای توالی مقادیر آینده را پیش بینی می کند.
دو رویکرد وجود دارد:
- پیش بینی های تک شات که در آن یکباره کل سری زمانی پیش بینی می شود.
- پیش بینی های خود همیسته که در آن مدل فقط پیش بینی های تک مرحله ای را انجام می دهد و خروجی آن به عنوان ورودی خود بازگردانده می شود.
در این بخش، تمام مدل ها تمام ویژگی ها را در تمام مراحل زمان خروجی پیش بینی می کنند.
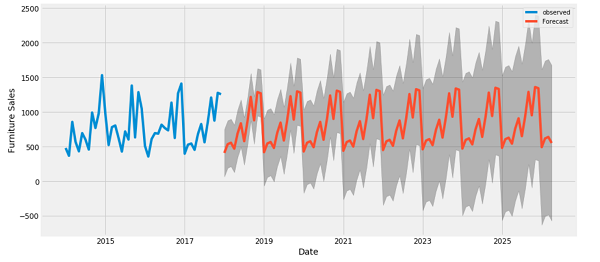
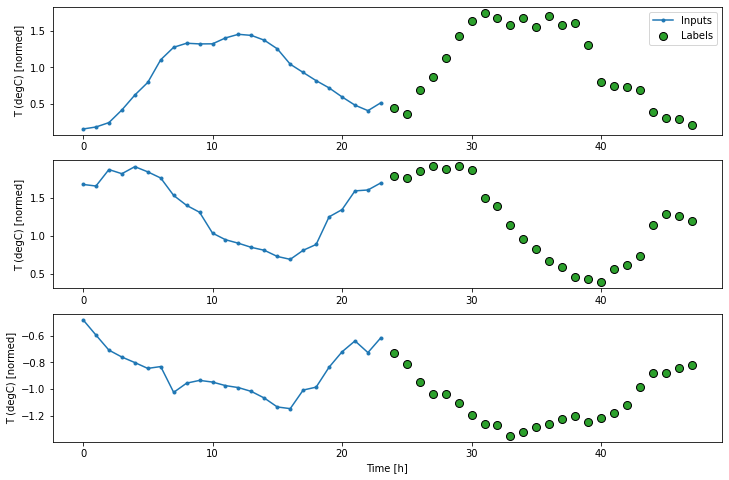
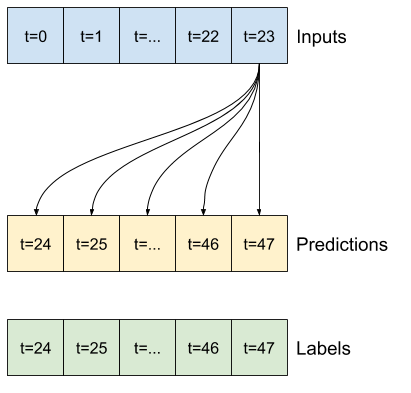
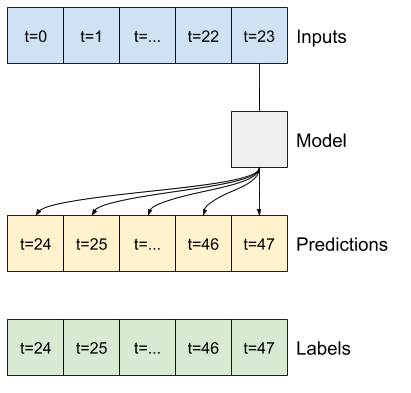
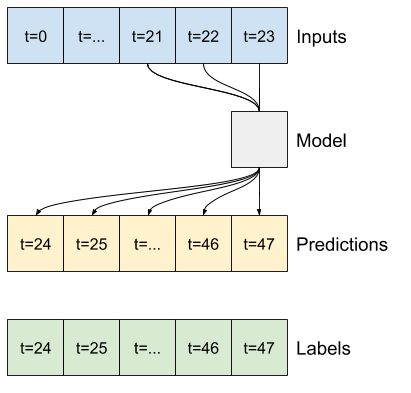
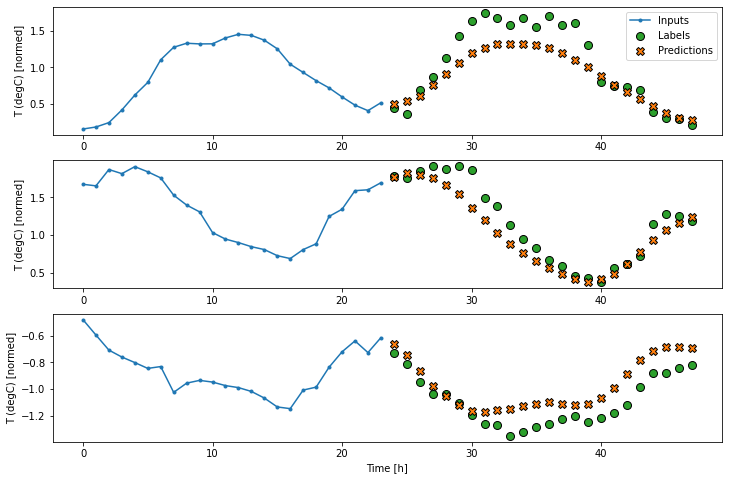
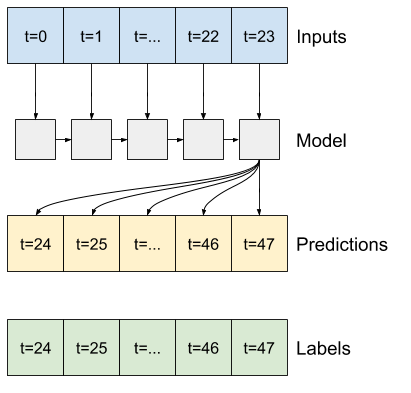
برای مدل چند مرحله ای، داده های آموزش دوباره از نمونه های ساعتی تشکیل شده است. با این حال، در اینجا، مدل ها یاد می گیرند که 24 ساعت از آینده را با توجه به 24 ساعت گذشته پیش بینی کنند.
در اینجا یک شی Window وجود دارد که این برشها را از مجموعه داده تولید می کند:
OUT_STEPS = 24
multi_window = WindowGenerator(input_width=24,
label_width=OUT_STEPS,
shift=OUT_STEPS)
multi_window.plot()
multi_windowTotal window size: 48 Input indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23] Label indices: [24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47] Label column name(s): None
خطوط پایه
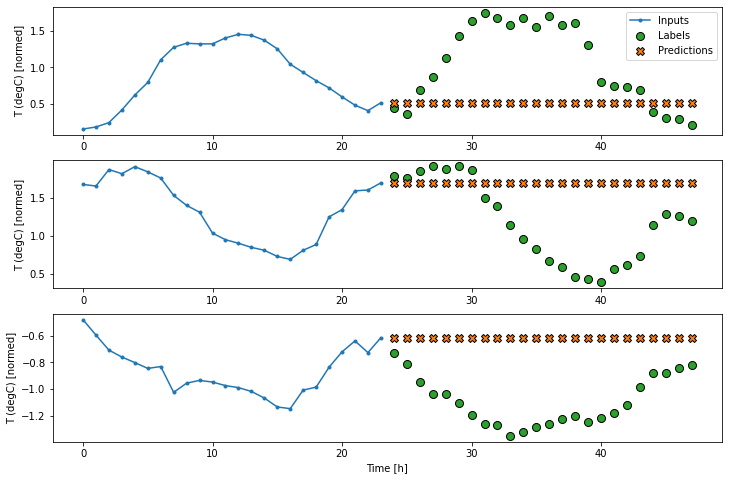
یک خط پایه ساده برای این کار تکرار آخرین مرحله زمان ورودی برای تعداد مورد نیاز بازه های زمانی است:
class MultiStepLastBaseline(tf.keras.Model):
def call(self, inputs):
return tf.tile(inputs[:, -1:, :], [1, OUT_STEPS, 1])
last_baseline = MultiStepLastBaseline()
last_baseline.compile(loss=tf.losses.MeanSquaredError(),
metrics=[tf.metrics.MeanAbsoluteError()])
multi_val_performance = {}
multi_performance = {}
multi_val_performance['Last'] = last_baseline.evaluate(multi_window.val)
multi_performance['Last'] = last_baseline.evaluate(multi_window.test, verbose=0)
multi_window.plot(last_baseline)437/437 [==============================] - 1s 2ms/step - loss: 0.6279 - mean_absolute_error: 0.5001
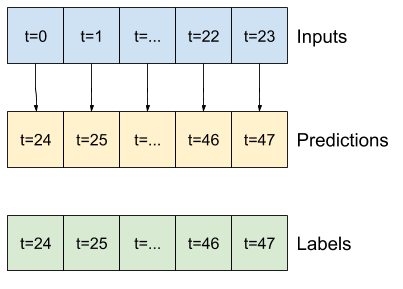
از آنجا که این وظیفه پیش بینی 24 ساعته، 24 ساعته است، رویکرد ساده دیگر تکرار روز قبل است، فرض کنید فردا مشابه باشد:
class RepeatBaseline(tf.keras.Model):
def call(self, inputs):
return inputs
repeat_baseline = RepeatBaseline()
repeat_baseline.compile(loss=tf.losses.MeanSquaredError(),
metrics=[tf.metrics.MeanAbsoluteError()])
multi_val_performance['Repeat'] = repeat_baseline.evaluate(multi_window.val)
multi_performance['Repeat'] = repeat_baseline.evaluate(multi_window.test, verbose=0)
multi_window.plot(repeat_baseline)437/437 [==============================] - 1s 3ms/step - loss: 0.4262 - mean_absolute_error: 0.3955
مدل های تک شات
یک رویکرد سطح بالا برای این مشکل استفاده از مدل "تک شات" است، که در آن مدل کل پیش بینی توالی را در یک مرحله انجام می دهد.
این را می توان به صورت layers.Dense به طور کارآمد پیاده سازی کرد. با OUT_STEPS*features خروجی واحد. مدل فقط باید آن خروجی را به اندازه مورد نیاز تغییر دهد (OUTPUT_STEPS, features).
خطی
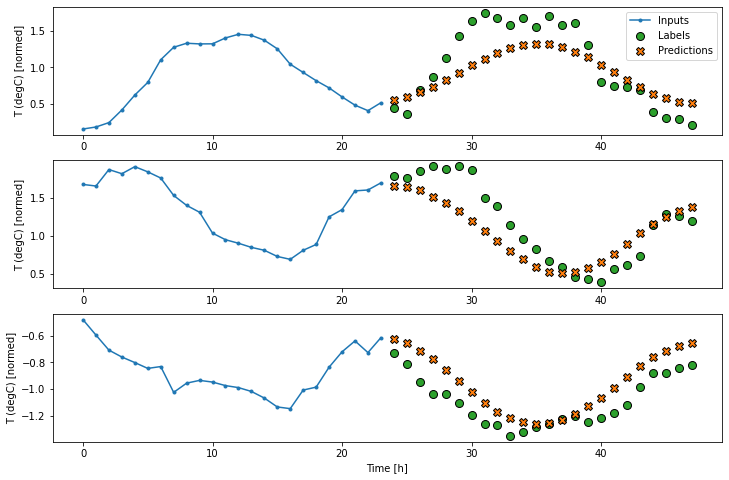
یک مدل خطی ساده بر اساس آخرین مرحله زمان ورودی بهتر از هر دو حالت پایه است، اما کم نیرو است. مدل باید از یک مرحله زمان ورودی واحد با یک طرح ریزی خطی، مراحل OUTPUT_STEPS را پیش بینی کند. این فقط می تواند یک برش کم بعدی از رفتار را ثبت کند، که احتمالاً بیشتر بر اساس زمان روز و زمان سال است.
multi_linear_model = tf.keras.Sequential([
# Take the last time-step.
# Shape [batch, time, features] => [batch, 1, features]
tf.keras.layers.Lambda(lambda x: x[:, -1:, :]),
# Shape => [batch, 1, out_steps*features]
tf.keras.layers.Dense(OUT_STEPS*num_features,
kernel_initializer=tf.initializers.zeros),
# Shape => [batch, out_steps, features]
tf.keras.layers.Reshape([OUT_STEPS, num_features])
])
history = compile_and_fit(multi_linear_model, multi_window)
IPython.display.clear_output()
multi_val_performance['Linear'] = multi_linear_model.evaluate(multi_window.val)
multi_performance['Linear'] = multi_linear_model.evaluate(multi_window.test, verbose=0)
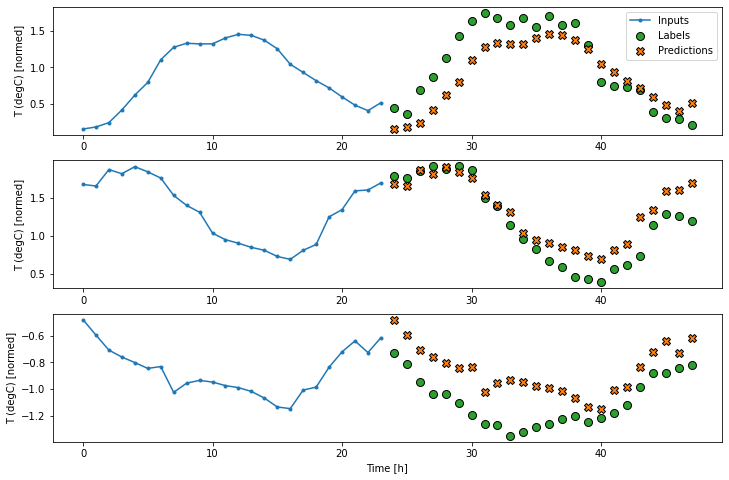
multi_window.plot(multi_linear_model)437/437 [==============================] - 1s 2ms/step - loss: 0.2559 - mean_absolute_error: 0.3049
تراکم
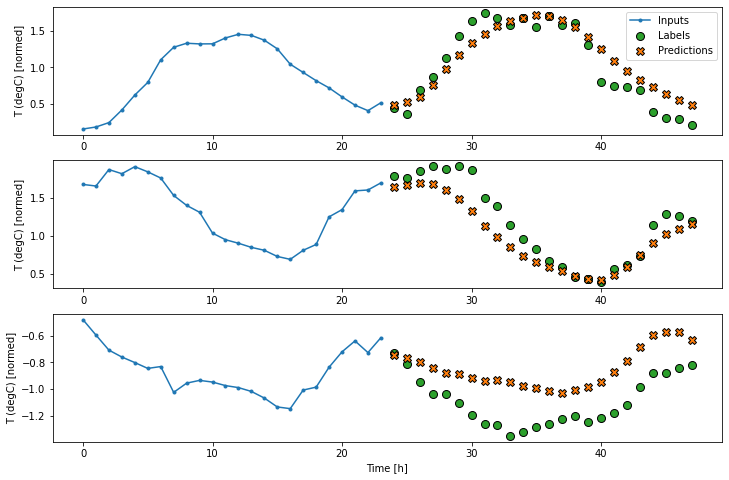
افزودن layers.Dense. متراکم بین ورودی و خروجی به مدل خطی قدرت بیشتری می بخشد، اما هنوز فقط براساس یک بازه زمانی ورودی واحد است.
multi_dense_model = tf.keras.Sequential([
# Take the last time step.
# Shape [batch, time, features] => [batch, 1, features]
tf.keras.layers.Lambda(lambda x: x[:, -1:, :]),
# Shape => [batch, 1, dense_units]
tf.keras.layers.Dense(512, activation='relu'),
# Shape => [batch, out_steps*features]
tf.keras.layers.Dense(OUT_STEPS*num_features,
kernel_initializer=tf.initializers.zeros),
# Shape => [batch, out_steps, features]
tf.keras.layers.Reshape([OUT_STEPS, num_features])
])
history = compile_and_fit(multi_dense_model, multi_window)
IPython.display.clear_output()
multi_val_performance['Dense'] = multi_dense_model.evaluate(multi_window.val)
multi_performance['Dense'] = multi_dense_model.evaluate(multi_window.test, verbose=0)
multi_window.plot(multi_dense_model)437/437 [==============================] - 1s 3ms/step - loss: 0.2190 - mean_absolute_error: 0.2821
CNN
یک مدل کانولوشن بر اساس تاریخچه ای با عرض ثابت پیش بینی می کند، که ممکن است عملکرد بهتری نسبت به مدل متراکم داشته باشد، زیرا می تواند تغییر وضعیت را در طول زمان مشاهده کند:
CONV_WIDTH = 3
multi_conv_model = tf.keras.Sequential([
# Shape [batch, time, features] => [batch, CONV_WIDTH, features]
tf.keras.layers.Lambda(lambda x: x[:, -CONV_WIDTH:, :]),
# Shape => [batch, 1, conv_units]
tf.keras.layers.Conv1D(256, activation='relu', kernel_size=(CONV_WIDTH)),
# Shape => [batch, 1, out_steps*features]
tf.keras.layers.Dense(OUT_STEPS*num_features,
kernel_initializer=tf.initializers.zeros),
# Shape => [batch, out_steps, features]
tf.keras.layers.Reshape([OUT_STEPS, num_features])
])
history = compile_and_fit(multi_conv_model, multi_window)
IPython.display.clear_output()
multi_val_performance['Conv'] = multi_conv_model.evaluate(multi_window.val)
multi_performance['Conv'] = multi_conv_model.evaluate(multi_window.test, verbose=0)
multi_window.plot(multi_conv_model)437/437 [==============================] - 1s 3ms/step - loss: 0.2171 - mean_absolute_error: 0.2814
RNN
اگر مربوط به پیش بینی های مدل باشد، یک مدل مکرر می تواند یاد بگیرد که از سابقه طولانی ورودی استفاده کند. در اینجا مدل قبل از پیش بینی 24 ساعته بعدی، حالت داخلی را برای 24 ساعت جمع می کند.
در این قالب تک شات، LSTM فقط باید در آخرین مرحله زمان خروجی تولید کند، بنابراین return_sequences=False تنظیم کنید.
multi_lstm_model = tf.keras.Sequential([
# Shape [batch, time, features] => [batch, lstm_units]
# Adding more `lstm_units` just overfits more quickly.
tf.keras.layers.LSTM(32, return_sequences=False),
# Shape => [batch, out_steps*features]
tf.keras.layers.Dense(OUT_STEPS*num_features,
kernel_initializer=tf.initializers.zeros),
# Shape => [batch, out_steps, features]
tf.keras.layers.Reshape([OUT_STEPS, num_features])
])
history = compile_and_fit(multi_lstm_model, multi_window)
IPython.display.clear_output()
multi_val_performance['LSTM'] = multi_lstm_model.evaluate(multi_window.val)
multi_performance['LSTM'] = multi_lstm_model.evaluate(multi_window.test, verbose=0)
multi_window.plot(multi_lstm_model)437/437 [==============================] - 1s 3ms/step - loss: 0.2170 - mean_absolute_error: 0.2856

پیشرفته: مدل خود همبسته
مدل های فوق همه توالی خروجی را در یک مرحله پیش بینی می کنند.
در بعضی موارد تجزیه این پیش بینی در مراحل زمانی منفرد برای مدل مفید است. سپس می توان خروجی هر مدل را در هر مرحله به خود بازگرداند و پیش بینی ها را می توان به مورد قبلی بستگی داشت، مانند توالی های تولید کلاسیک با شبکه های عصبی عودکننده.
یکی از مزایای بارز این سبک مدل این است که می تواند برای تولید خروجی با طول متفاوت تنظیم شود.
شما می توانید هر یک از مدلهای چند مرحله ای تک مرحله ای را که در نیمه اول این آموزش آموزش دیده اند، انجام دهید و در یک حلقه بازخورد خود رگرسیون اجرا کنید، اما در اینجا شما بر ساخت مدلی تمرکز خواهید کرد که صریحاً برای انجام آن آموزش دیده است.

RNN
این آموزش فقط یک مدل RNN خود رگرسیون می سازد، اما این الگو را می توان برای هر مدلی که برای تولید یک گام زمان طراحی شده است، اعمال کرد.
این مدل همان شکل اولیه را دارد که مدلهای LSTM تک مرحله ای دارند: LSTM که به دنبال آن layers.Dense ارائه می شود. که خروجی های LSTM را به پیش بینی های مدل تبدیل می کند.
یک layers.LSTMیک layers.LSTMCell که سلول در layers.RNN سطح بالاتر قرار دارد. RNN که وضعیت و ترتیب را برای شما مدیریت می کند (برای جزئیات بیشتر به RNN های Keras مراجعه کنید).
در این حالت مدل مجبور است ورودی ها را برای هر مرحله به صورت دستی مدیریت کند بنابراین از لایه ها استفاده می کند. layers.LSTMCell مستقیماً برای سطح پایین تر، رابط مرحله تک زمانه.
class FeedBack(tf.keras.Model):
def __init__(self, units, out_steps):
super().__init__()
self.out_steps = out_steps
self.units = units
self.lstm_cell = tf.keras.layers.LSTMCell(units)
# Also wrap the LSTMCell in an RNN to simplify the `warmup` method.
self.lstm_rnn = tf.keras.layers.RNN(self.lstm_cell, return_state=True)
self.dense = tf.keras.layers.Dense(num_features)feedback_model = FeedBack(units=32, out_steps=OUT_STEPS)
اولین روشی که این مدل به آن احتیاج دارد، یک روشwarmup برای شروع حالت داخلی آن بر اساس ورودی ها است. پس از آموزش، این حالت قسمتهای مربوط به تاریخچه ورودی را ضبط می کند. این معادل مدل LSTM تک مرحله ای قبلی است:
def warmup(self, inputs):
# inputs.shape => (batch, time, features)
# x.shape => (batch, lstm_units)
x, *state = self.lstm_rnn(inputs)
# predictions.shape => (batch, features)
prediction = self.dense(x)
return prediction, state
FeedBack.warmup = warmupاین روش یک پیش بینی زمان گام واحد و وضعیت داخلی LSTM را برمی گرداند:
prediction, state = feedback_model.warmup(multi_window.example[0])
prediction.shapeTensorShape([32, 19])
با وضعیت RNN و پیش بینی اولیه اکنون می توانید تکرار مدل تغذیه کننده پیش بینی ها را در هر مرحله به عنوان ورودی ادامه دهید.
ساده ترین روش برای جمع آوری پیش بینی های خروجی استفاده از لیست پایتون و tf.stack پس از حلقه است.
توجه: انباشته کردن لیست پایتون مانند این فقط با اجرای مشتاقانه، با استفاده از Model.compile (...، run_eagerly = True) برای آموزش یا با یک خروجی با طول ثابت کار می کند. برای یک طول خروجی پویا، شما باید از tf.TensorArray به جای لیست پایتون و tf.range به جای محدوده پایتون استفاده کنید.
def call(self, inputs, training=None):
# Use a TensorArray to capture dynamically unrolled outputs.
predictions = []
# Initialize the lstm state
prediction, state = self.warmup(inputs)
# Insert the first prediction
predictions.append(prediction)
# Run the rest of the prediction steps
for n in range(1, self.out_steps):
# Use the last prediction as input.
x = prediction
# Execute one lstm step.
x, state = self.lstm_cell(x, states=state,
training=training)
# Convert the lstm output to a prediction.
prediction = self.dense(x)
# Add the prediction to the output
predictions.append(prediction)
# predictions.shape => (time, batch, features)
predictions = tf.stack(predictions)
# predictions.shape => (batch, time, features)
predictions = tf.transpose(predictions, [1, 0, 2])
return predictions
FeedBack.call = callprint('Output shape (batch, time, features): ', feedback_model(multi_window.example[0]).shape)
Output shape (batch, time, features): (32, 24, 19)
اکنون مدل را آموزش دهید:
history = compile_and_fit(feedback_model, multi_window)
IPython.display.clear_output()
multi_val_performance['AR LSTM'] = feedback_model.evaluate(multi_window.val)
multi_performance['AR LSTM'] = feedback_model.evaluate(multi_window.test, verbose=0)
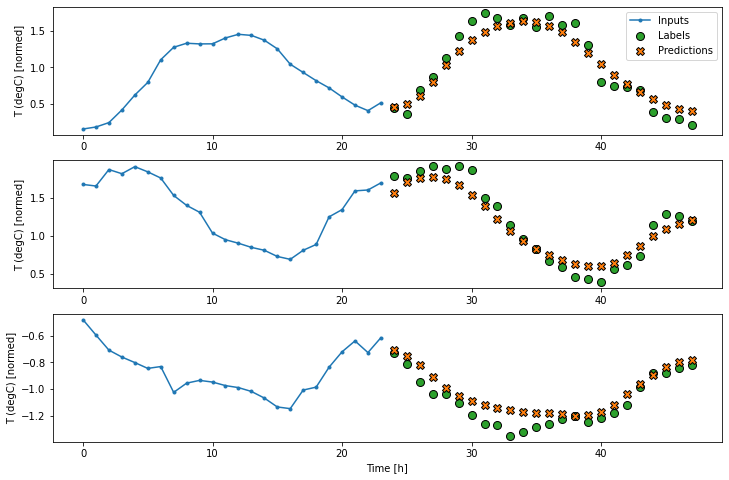
multi_window.plot(feedback_model)437/437 [==============================] - 3s 7ms/step - loss: 0.2240 - mean_absolute_error: 0.2982
کارایی
بازدهی به وضوح در حال کاهش است که تابعی از پیچیدگی مدل در این مسئله است.
x = np.arange(len(multi_performance))
width = 0.3
metric_name = 'mean_absolute_error'
metric_index = lstm_model.metrics_names.index('mean_absolute_error')
val_mae = [v[metric_index] for v in multi_val_performance.values()]
test_mae = [v[metric_index] for v in multi_performance.values()]
plt.bar(x - 0.17, val_mae, width, label='Validation')
plt.bar(x + 0.17, test_mae, width, label='Test')
plt.xticks(ticks=x, labels=multi_performance.keys(),
rotation=45)
plt.ylabel(f'MAE (average over all times and outputs)')
_ = plt.legend()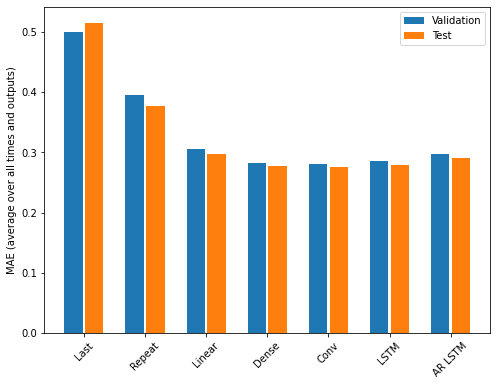
معیارهای مدل های چند خروجی در نیمه اول این آموزش ، عملکرد متوسط در تمام ویژگی های خروجی را نشان می دهد. این عملکردها در بازه های زمانی خروجی مشابه هستند اما به طور متوسط هستند.
for name, value in multi_performance.items():
print(f'{name:8s}: {value[1]:0.4f}')Last : 0.5157 Repeat : 0.3774 Linear : 0.2979 Dense : 0.2769 Conv : 0.2750 LSTM : 0.2797 AR LSTM : 0.2904
دستاوردهایی که از یک مدل متراکم به مدلهای کانولوشن و تکرار شونده بدست آمده تنها چند درصد است (در صورت وجود) و عملکرد خود رگرسیون به وضوح بدتر است. بنابراین این رویکردهای پیچیده تر ممکن است ارزش استفاده از این مشکل را نداشته باشند ، اما راهی برای دانستن بدون تلاش وجود نداشت و این مدل ها می توانند برای مشکل شما مفید باشند.


مدیر سایت: بهزاد سرهادی کارشناس ارشد مهندسی آب
شناسه تلگرام مدیر سایت: SubBasin@
نشانی ایمیل: behzadsarhadi@gmail.com
(سوالات تخصصی را در گروه تلگرام ارسال کنید)
_______________________________________________________
پروژه تخصصی در لینکدین



 در منابع آب
در منابع آب


























نظرات (۰)