



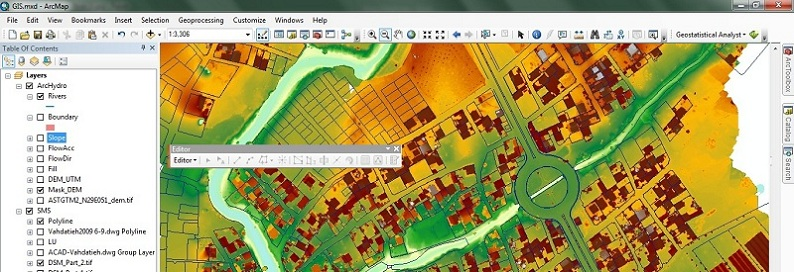
مدل سازی احتمالاتی با GMS
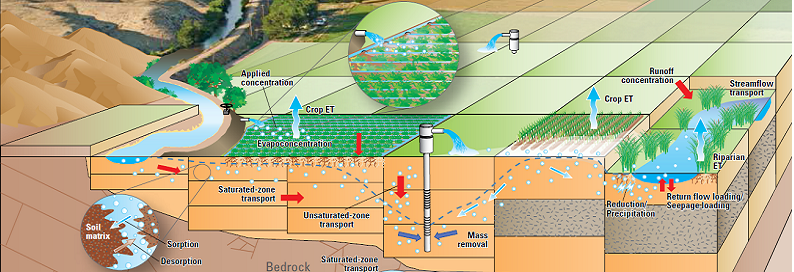
مقدار قابل توجهی از عدم قطعیت همیشه با یک مدل آب زیرزمینی همراه است. این عدم قطعیت می تواند با مدل مفهومی یا با داده ها و پارامترهای مرتبط با اجزای مختلف مدل مرتبط باشد. برخی از پارامترهای مدل - مانند هدایت هیدرولیکی و شارژ مجدد - به ویژه مستعد عدم قطعیت هستند. کالیبره کردن یک مدل به مجموعه ای غنی از داده های مشاهداتی (چاه های نظارت، جریان و غیره) ممکن است تا حدودی این عدم قطعیت را کاهش دهد. با این حال، داده های کالیبراسیون اغلب کمیاب هستند، و حتی مدل های به خوبی کالیبره شده دارای سطح بالایی از عدم قطعیت هستند.
یکی از روشهای مقابله با عدم قطعیت، استفاده از رویکرد مدلسازی تصادفی است. با یک رویکرد غیر تصادفی، یک مدل واحد توسعه یافته است که بهترین تخمین از سیستم واقعی شبیهسازی شده را نشان میدهد. این مدل برای پیش بینی استفاده می شود.
با یک رویکرد تصادفی، مجموعهای از مدلها ساخته میشوند که در آن هر مدل در مجموعه به یک اندازه احتمال دارد. سپس از هر مدل برای پیشبینی یا شبیهسازی یک سناریوی معین استفاده میشود و از نتایج برای تخمین احتمال یا خطر وقوع یک نتیجه خاص استفاده میشود. در حالی که این رویکرد همچنان بر مفروضات مدل اساسی برای تولید تخمینهای پارامتر اولیه متکی است، اما صادقانهتر عدم قطعیت مرتبط با مدلسازی را منعکس میکند.
GMS شامل دو روش اساسی برای تولید شبیهسازی تصادفی است: تصادفیسازی پارامترها و شبیهسازی نشانگر. با روش تصادفی سازی پارامترها، پارامترهای مدل انتخاب شده با استفاده از روش نمونه گیری تصادفی یا Hypercube لاتین تصادفی می شوند. هر ترکیبی از پارامترهای ورودی یک نمونه مدل را تعریف می کند. با رویکرد شبیهسازی شاخص، تحققهای چندگانه به همان اندازه احتمالی ناهمگونی آبخوان تولید میشوند و هر تحقق برای تعریف یک نمونه مدل استفاده میشود.
GMS دو روش را برای انجام تصادفی سازی پارامترها ارائه می دهد: نمونه برداری تصادفی و Hypercube لاتین. با روش نمونه گیری تصادفی برای هر پارامتر یک میانگین، یک انحراف استاندارد، یک مقدار حداقل و یک مقدار حداکثر مشخص می شود. بعلاوه، پارامتر را می توان به صورت log تبدیل شده مشخص کرد، که معمولاً برای هدایت هیدرولیکی صادق است.
تعداد شبیه سازی ها نیز مشخص شده است. برای هر شبیه سازی، یک عدد تصادفی برای هر پارامتر با توجه به توزیع مشخص شده با استفاده از میانگین، انحراف استاندارد، حداکثر و حداقل تولید می شود. GMS از هر دو توزیع نرمال و یکنواخت پشتیبانی می کند. هر چه شبیه سازی های بیشتری تولید شود، اطمینان بیشتری نسبت به بررسی همه گزینه ها وجود دارد.
روش لاتین Hypercube یک جایگزین جذاب برای روش نمونهگیری تصادفی است زیرا امکان اطمینان بیشتر با اجرای مدلهای کمتر را فراهم میکند. این می تواند به ویژه برای مدل های پیچیده ای که به زمان محاسباتی زیادی نیاز دارند مفید باشد.
همانند روش نمونهگیری تصادفی، میانگین، انحراف استاندارد، حداقل، حداکثر و تعداد بخشها برای هر پارامتر برای هر پارامتر مشخص میشود. سپس منحنی توزیع احتمال برای هر پارامتر به n بخش با احتمال مساوی تقسیم می شود.
ایده پشت رویکرد لاتین Hypercube این است که فضای پارامتر (تمام ترکیبات ممکن از مقادیر پارامتر) باید تا حد امکان کامل با تعداد محدودی از مدلها نمونهبرداری شود. هنگامی که بخش ها تعریف می شوند، هر پارامتر به صورت تصادفی تا زمانی که مقداری که در هر بخش احتمال قرار دارد، پیدا شود. اعداد تصادفی برای هر پارامتر با اعداد تصادفی سایر پارامترها ترکیب می شوند به طوری که تمام ترکیبات ممکن از بخش ها نمونه برداری می شوند. تعداد کل اجراهای مدل حاصل ضرب تعداد بخش ها برای هر پارامتر است. به عنوان مثال، اگر سه پارامتر با چهار بخش و یکی با پنج بخش وجود داشته باشد، تعداد کل شبیه سازی ها 4 * 4 * 4 * 5 = 320 خواهد بود. در GMS، مساحت کل زیر منحنی احتمال بیشتر با مقدار مشخص شده محدود می شود. محدوده پارامتر حداکثر و حداقل این حداکثر دامنه پارامتر را می دهد و در عین حال بهترین شانس را برای پایداری مدل حفظ می کند. اطمینان بیشتر از تعداد اجراهای کمتر ناشی از تضمین این است که مجموعه کاملتری از ترکیبات پارامترها آزمایش شده است.
راهنمای اساسی را در اینجا مطالعه کنید.

مدیر سایت: بهزاد سرهادی کارشناس ارشد مهندسی آب
شناسه تلگرام مدیر سایت: SubBasin@
نشانی ایمیل: behzadsarhadi@gmail.com
(سوالات تخصصی را در گروه تلگرام ارسال کنید)
_______________________________________________________
پروژه تخصصی در لینکدین



 در منابع آب
در منابع آب


























نظرات (۰)