



پیش بینی سری زمانی داده های آب و هوا در پایتون
در علوم مختلف، به یک توالی یا دنباله از متغیرهای تصادفی که در فاصله های زمانی ثابت نمونه برداری شده باشند، اصطلاحاً سری زمانی یا پیشامد تصادفی در مقطع زمان میگویند. به عبارت دیگر منظور از یک سری زمانی مجموعهای از دادههای آماری است که در فواصل زمانی مساوی و منظمی جمعآوری شده باشند. روشهای آماری ای که این گونه دادههای آماری را مورد استفاده قرار میدهد مدل های تحلیل سری زمانی نامیده میشود. مانند فروش فصلی یک شرکت طی سه سال گذشته. یک سری زمانی مجموعهٔ مشاهدات تصادفی ای است که بر اساس زمان مرتب شده باشند. مثالهای آن در اقتصاد و حتی رشتههای مهندسی دیده میشود.
این کد نحوه انجام پیش بینی جدول زمانی را با استفاده از مدل LSTM نشان می دهد.
نصب
این مثال به TensorFlow 2.3 یا بالاتر نیاز دارد.
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import kerasسری زمانی داده های اقلیمی
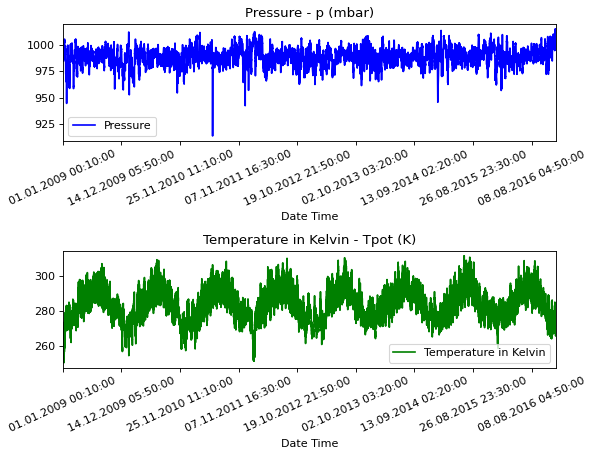
ما از مجموعه داده های آب و هوای Jena که توسط موسسه بیوژئوشیمی ماکس پلانک ثبت شده استفاده خواهیم کرد. این مجموعه داده شامل 14 ویژگی مانند دما، فشار، رطوبت و غیره است که هر 10 دقیقه یک بار ثبت می شود.
مکان: ایستگاه هواشناسی، موسسه بیوژئوشیمی ماکس پلانک در ینا، آلمان
چارچوب زمانی مورد بررسی: 10 ژانویه 2009 - 31 دسامبر 2016
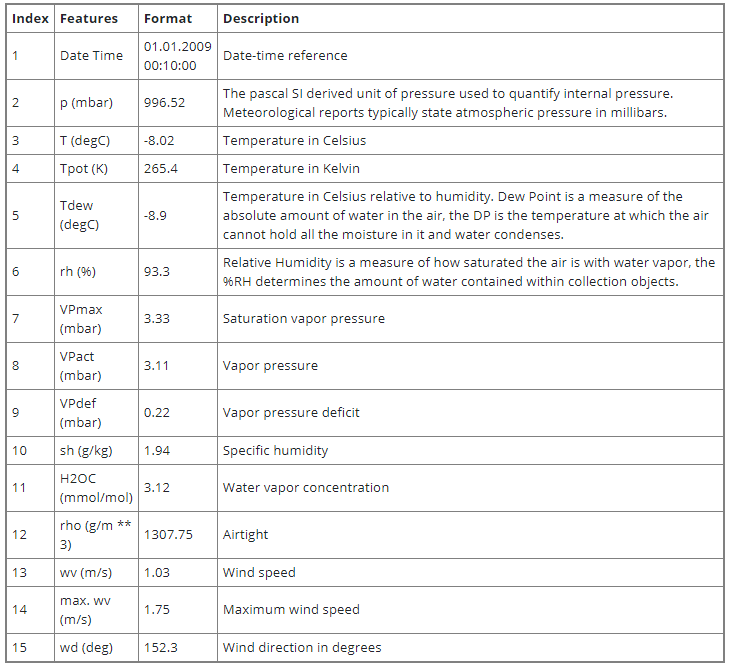
جدول زیر نام ستون ها، قالب های ارزش آنها و توضیحات آنها را نشان می دهد.
from zipfile import ZipFile
import os
uri = "https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip"
zip_path = keras.utils.get_file(origin=uri, fname="jena_climate_2009_2016.csv.zip")
zip_file = ZipFile(zip_path)
zip_file.extractall()
csv_path = "jena_climate_2009_2016.csv"
df = pd.read_csv(csv_path)تجسم داده های خام
برای درک بخشی از داده هایی که با آنها کار می کنیم، هر ویژگی در زیر ترسیم شده است. این الگوی متمایز هر ویژگی را در بازه زمانی 2009 تا 2016 نشان می دهد. همچنین نشان می دهد ناهنجاری ها در کجا وجود دارند که در هنگام عادی سازی برطرف می شوند.
titles = [
"Pressure",
"Temperature",
"Temperature in Kelvin",
"Temperature (dew point)",
"Relative Humidity",
"Saturation vapor pressure",
"Vapor pressure",
"Vapor pressure deficit",
"Specific humidity",
"Water vapor concentration",
"Airtight",
"Wind speed",
"Maximum wind speed",
"Wind direction in degrees",
]
feature_keys = [
"p (mbar)",
"T (degC)",
"Tpot (K)",
"Tdew (degC)",
"rh (%)",
"VPmax (mbar)",
"VPact (mbar)",
"VPdef (mbar)",
"sh (g/kg)",
"H2OC (mmol/mol)",
"rho (g/m**3)",
"wv (m/s)",
"max. wv (m/s)",
"wd (deg)",
]
colors = [
"blue",
"orange",
"green",
"red",
"purple",
"brown",
"pink",
"gray",
"olive",
"cyan",
]
date_time_key = "Date Time"
def show_raw_visualization(data):
time_data = data[date_time_key]
fig, axes = plt.subplots(
nrows=7, ncols=2, figsize=(15, 20), dpi=80, facecolor="w", edgecolor="k"
)
for i in range(len(feature_keys)):
key = feature_keys[i]
c = colors[i % (len(colors))]
t_data = data[key]
t_data.index = time_data
t_data.head()
ax = t_data.plot(
ax=axes[i // 2, i % 2],
color=c,
title="{} - {}".format(titles[i], key),
rot=25,
)
ax.legend([titles[i]])
plt.tight_layout()
show_raw_visualization(df)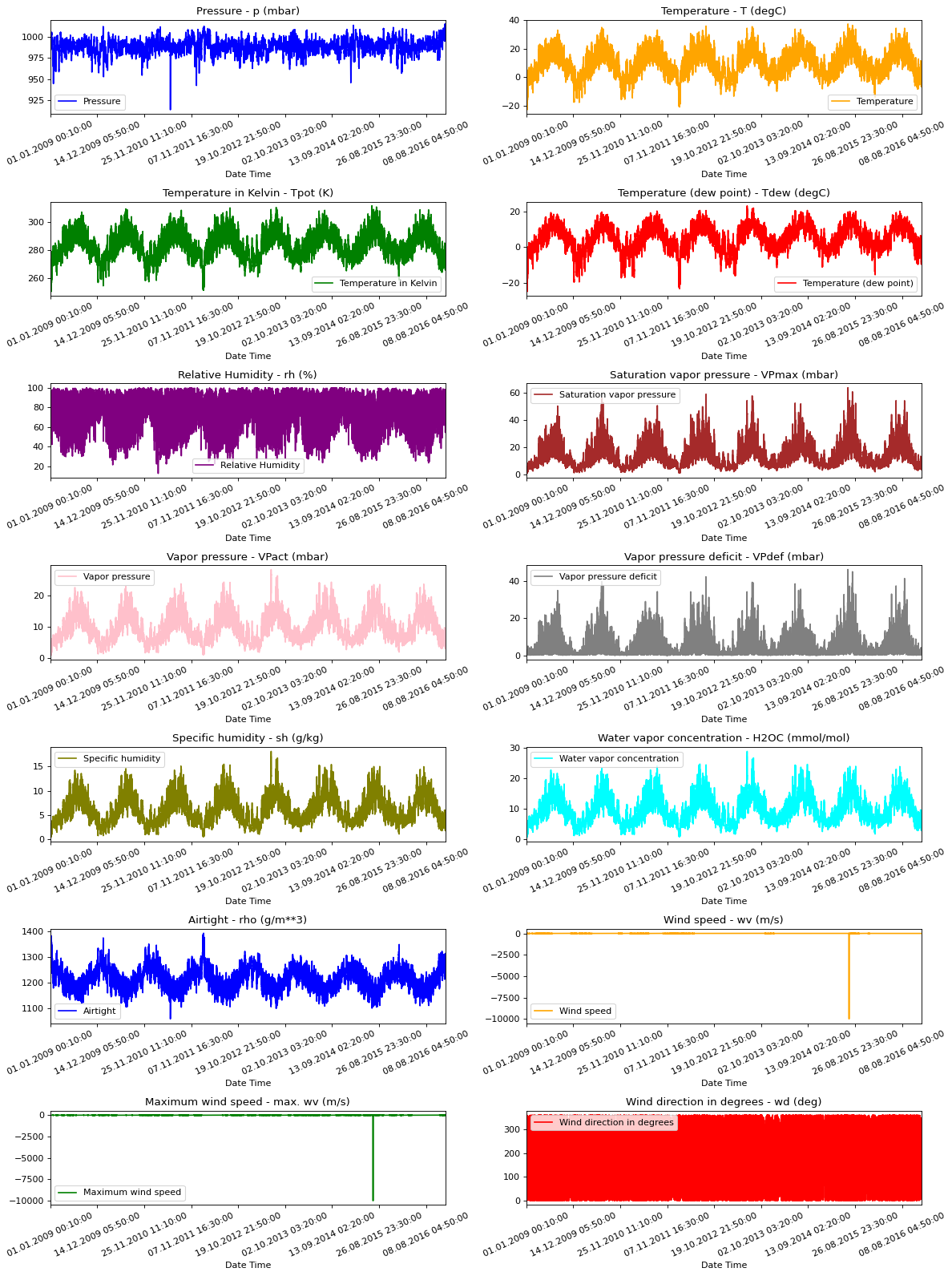
این نقشه حرارتی همبستگی بین ویژگی های مختلف را نشان می دهد.
def show_heatmap(data):
plt.matshow(data.corr())
plt.xticks(range(data.shape[1]), data.columns, fontsize=14, rotation=90)
plt.gca().xaxis.tick_bottom()
plt.yticks(range(data.shape[1]), data.columns, fontsize=14)
cb = plt.colorbar()
cb.ax.tick_params(labelsize=14)
plt.title("Feature Correlation Heatmap", fontsize=14)
plt.show()
show_heatmap(df)
پیش پردازش داده ها
در اینجا ما 300،000 پوند امتیاز داده برای آموزش انتخاب می کنیم. مشاهده هر 10 دقیقه ثبت می شود، یعنی 6 بار در ساعت. ما یک نقطه در ساعت را مثال می زنیم زیرا در عرض 60 دقیقه هیچ تغییر اساسی انتظار نمی رود. ما این کار را از طریق آرگومان sampling_rate در برنامه timeseries_dataset_from_array انجام می دهیم.
در حال ردیابی داده های 720 لحظه زمان گذشته (720/6 = 120 ساعت) هستیم. این داده ها برای پیش بینی دما بعد از 72 لحظه زمان (76/6 = 12 ساعت) استفاده می شود.
از آنجا که هر ویژگی مقادیری با دامنه های مختلف دارد، ما عادی سازی می کنیم تا مقادیر ویژگی را در محدوده [0، 1] قبل از آموزش شبکه عصبی محدود کنیم. این کار را با کم کردن میانگین و تقسیم بر انحراف معیار هر ویژگی انجام می دهیم.
مقدار 71/5 درصد از داده ها برای آموزش مدل استفاده می شود، یعنی 300،693 ردیف. split_faction را می توان تغییر داد تا این درصد تغییر کند.
این مدل داده های 5 روز اول یعنی 720 مشاهده را نشان می دهد که هر ساعت نمونه برداری می شود. دما بعد از 72 مشاهده (12 ساعت * 6 مشاهده در ساعت) به عنوان برچسب استفاده می شود.
split_fraction = 0.715
train_split = int(split_fraction * int(df.shape[0]))
step = 6
past = 720
future = 72
learning_rate = 0.001
batch_size = 256
epochs = 10
def normalize(data, train_split):
data_mean = data[:train_split].mean(axis=0)
data_std = data[:train_split].std(axis=0)
return (data - data_mean) / data_stdاز نقشه گرمای همبستگی می توان فهمید که پارامترهای کمی مانند رطوبت نسبی و رطوبت خاص زاید هستند. از این رو ما از ویژگی های انتخابی استفاده خواهیم کرد، نه همه.
print(
"The selected parameters are:",
", ".join([titles[i] for i in [0, 1, 5, 7, 8, 10, 11]]),
)
selected_features = [feature_keys[i] for i in [0, 1, 5, 7, 8, 10, 11]]
features = df[selected_features]
features.index = df[date_time_key]
features.head()
features = normalize(features.values, train_split)
features = pd.DataFrame(features)
features.head()
train_data = features.loc[0 : train_split - 1]
val_data = features.loc[train_split:]The selected parameters are: Pressure, Temperature, Saturation vapor pressure, Vapor pressure deficit, Specific humidity, Airtight, Wind speed
مجموعه داده های آموزشی
برچسب های مجموعه آموزش از 792مین مشاهده آغاز می شود (720 + 72).
start = past + future
end = start + train_split
x_train = train_data[[i for i in range(7)]].values
y_train = features.iloc[start:end][[1]]
sequence_length = int(past / step)تابع timeseries_dataset_from_array دنباله ای از نقاط داده را با فواصل برابر جمع می کند، همراه با پارامترهای سری زمانی مانند طول دنباله ها / پنجره ها، فاصله بین دو توالی / پنجره ها و غیره، برای تولید دسته ای از ورودی ها و اهداف زیر بارگاه ها از خیابانهای اصلی نمونه برداری شده است.
dataset_train = keras.preprocessing.timeseries_dataset_from_array(
x_train,
y_train,
sequence_length=sequence_length,
sampling_rate=step,
batch_size=batch_size,
)مجموعه داده های اعتبار سنجی
مجموعه داده اعتبار سنجی نباید شامل 792 ردیف آخر باشد زیرا داده های برچسبی برای آن سوابق نخواهیم داشت، بنابراین 792 باید از انتهای داده ها کم شود.
x_end = len(val_data) - past - future
label_start = train_split + past + future
x_val = val_data.iloc[:x_end][[i for i in range(7)]].values
y_val = features.iloc[label_start:][[1]]
dataset_val = keras.preprocessing.timeseries_dataset_from_array(
x_val,
y_val,
sequence_length=sequence_length,
sampling_rate=step,
batch_size=batch_size,
)
for batch in dataset_train.take(1):
inputs, targets = batch
print("Input shape:", inputs.numpy().shape)
print("Target shape:", targets.numpy().shape)Input shape: (256, 120, 7)
Target shape: (256, 1)آموزش
inputs = keras.layers.Input(shape=(inputs.shape[1], inputs.shape[2]))
lstm_out = keras.layers.LSTM(32)(inputs)
outputs = keras.layers.Dense(1)(lstm_out)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer=keras.optimizers.Adam(learning_rate=learning_rate), loss="mse")
model.summary()Model: "functional_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 120, 7)] 0
_________________________________________________________________
lstm (LSTM) (None, 32) 5120
_________________________________________________________________
dense (Dense) (None, 1) 33
=================================================================
Total params: 5,153
Trainable params: 5,153
Non-trainable params: 0
_________________________________________________________________مجموعه داده های برچسب اعتبار سنجی باید از 792 پس از train_split شروع شود، بنابراین باید گذشته + آینده (792) را به label_start اضافه کنیم.
es_callback = keras.callbacks.EarlyStopping(monitor="val_loss", min_delta=0, patience=5)
modelckpt_callback = keras.callbacks.ModelCheckpoint(
monitor="val_loss",
filepath=path_checkpoint,
verbose=1,
save_weights_only=True,
save_best_only=True,
)
history = model.fit(
dataset_train,
epochs=epochs,
validation_data=dataset_val,
callbacks=[es_callback, modelckpt_callback],
)1172/1172 [==============================] - ETA: 0s - loss: 0.2059
Epoch 00001: val_loss improved from inf to 0.16357, saving model to model_checkpoint.h5
1172/1172 [==============================] - 101s 86ms/step - loss: 0.2059 - val_loss: 0.1636
Epoch 2/10
1172/1172 [==============================] - ETA: 0s - loss: 0.1271
Epoch 00002: val_loss improved from 0.16357 to 0.13362, saving model to model_checkpoint.h5
1172/1172 [==============================] - 107s 92ms/step - loss: 0.1271 - val_loss: 0.1336
Epoch 3/10
1172/1172 [==============================] - ETA: 0s - loss: 0.1089
Epoch 00005: val_loss did not improve from 0.13362
1172/1172 [==============================] - 110s 94ms/step - loss: 0.1089 - val_loss: 0.1481
Epoch 6/10
271/1172 [=====>........................] - ETA: 1:12 - loss: 0.1117ما برای ذخیره منظم ایست های بازرسی از پاسخگویی ModelCheckpoint و برای جلوگیری از آموزش در صورت عدم بهبود اعتبار سنجی، از پاسخ EarlyStopping استفاده می کنیم.
def visualize_loss(history, title):
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(len(loss))
plt.figure()
plt.plot(epochs, loss, "b", label="Training loss")
plt.plot(epochs, val_loss, "r", label="Validation loss")
plt.title(title)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
visualize_loss(history, "Training and Validation Loss")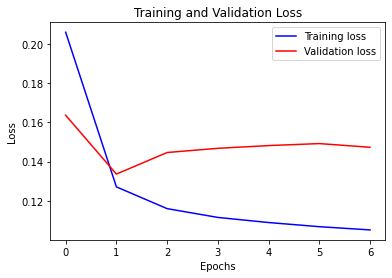
پیش بینی
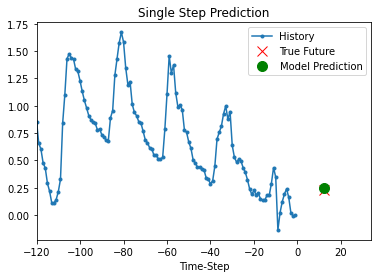
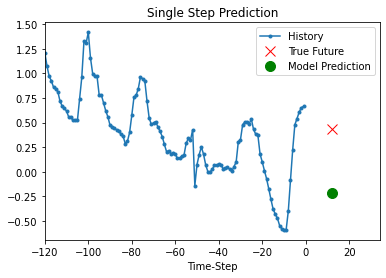
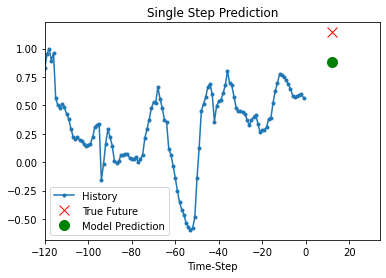
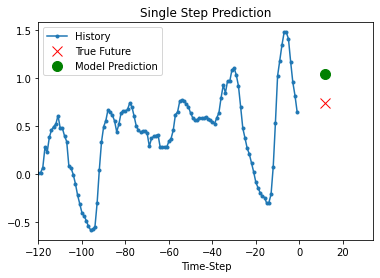
مدل آموزش دیده فوق اکنون قادر است 5 مجموعه مقادیر را از مجموعه اعتبار سنجی پیش بینی کند.
def show_plot(plot_data, delta, title):
labels = ["History", "True Future", "Model Prediction"]
marker = [".-", "rx", "go"]
time_steps = list(range(-(plot_data[0].shape[0]), 0))
if delta:
future = delta
else:
future = 0
plt.title(title)
for i, val in enumerate(plot_data):
if i:
plt.plot(future, plot_data[i], marker[i], markersize=10, label=labels[i])
else:
plt.plot(time_steps, plot_data[i].flatten(), marker[i], label=labels[i])
plt.legend()
plt.xlim([time_steps[0], (future + 5) * 2])
plt.xlabel("Time-Step")
plt.show()
return
for x, y in dataset_val.take(5):
show_plot(
[x[0][:, 1].numpy(), y[0].numpy(), model.predict(x)[0]],
12,
"Single Step Prediction",
)


مدیر سایت: بهزاد سرهادی کارشناس ارشد مهندسی آب
شناسه تلگرام مدیر سایت: SubBasin@
نشانی ایمیل: behzadsarhadi@gmail.com
(سوالات تخصصی را در گروه تلگرام ارسال کنید)
_______________________________________________________
پروژه تخصصی در لینکدین



 در منابع آب
در منابع آب


























نظرات (۰)