



پیش بینی با مدل های LSTM در کراس
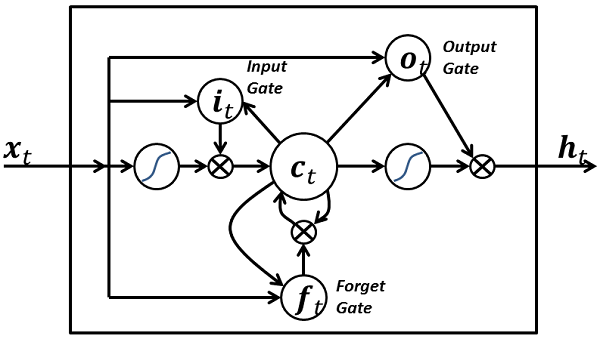
حافظه طولانی کوتاه-مدت (به انگلیسی: Long short-term memory) یا به اختصار الاستیام (تلفظ تحتاللفظی LSTM)، یک معماری شبکه عصبی بازگشتی (یک شبکه عصبی مصنوعی) است که در سال ۱۹۹۷ میلادی توسط سپ هوخرایتر و یورگن اشمیدهوبر ارائه شد، و بعداً در سال ۲۰۰۰ میلادی توسط فیلیکس ژرس بهبود داده شد.
هدف از توسعه مدل LSTM مدل نهایی است که می توانید از آن در مسئله پیش بینی توالی خود استفاده کنید. در این پست، شما خواهید فهمید که چگونه مدل خود را نهایی کنید و از آن برای پیش بینی داده های جدید استفاده کنید.
پس از تکمیل این پست، می دانید:
- نحوه آموزش مدل نهایی LSTM.
- چگونه مدل LSTM نهایی خود را ذخیره کرده و بعداً دوباره بارگیری کنیم.
- چگونه می توان داده های جدید را پیش بینی کرد.
پروژه خود را با کتاب جدید من شبکه های حافظه کوتاه مدت با پایتون، شامل آموزش گام به گام و فایلهای کد منبع پایتون برای همه مثالها، شروع کنید.
مرحله 1. یک مدل نهایی را آموزش دهید
مدل نهایی LSTM چیست؟
مدل نهایی LSTM مدلی است که شما برای پیش بینی داده های جدید استفاده می کنید.
یعنی با توجه به نمونه های جدید داده های ورودی، می خواهید از مدل برای پیش بینی خروجی مورد انتظار استفاده کنید. این ممکن است یک طبقه بندی (اختصاص یک برچسب) یا یک رگرسیون (یک مقدار واقعی) باشد.
هدف از پروژه پیش بینی توالی شما رسیدن به یک مدل نهایی است که بهترین عملکرد را داشته باشد، جایی که "بهترین" توسط این مطالب تعریف می شود:
- داده: داده های تاریخی که در دسترس دارید.
- زمان: زمانی که باید برای پروژه صرف کنید.
- روش کار: مراحل آماده سازی داده ها، الگوریتم یا الگوریتم ها و پیکربندی های الگوریتم انتخاب شده.
در پروژه خود، شما داده ها را جمع آوری می کنید، زمانی را که سپری می کنید و مراحل آماده سازی داده ها، الگوریتم استفاده و نحوه پیکربندی آنها را کشف می کنید.
مدل نهایی اوج این فرایند است، هدفی که شما برای شروع در واقع پیش بینی دنبال می کنید. چیزی به عنوان یک مدل کامل وجود ندارد. فقط بهترین مدلی وجود دارد که توانستید کشف کنید.
چگونه می توان یک مدل LSTM را نهایی کرد؟
شما با استفاده از ساختار و پیکربندی LSTM انتخاب شده روی تمام داده های خود، یک مدل را نهایی می کنید.
هیچ قطعه سعی و آزمونی وجود ندارد و هیچ اعتبارسنجی وجود ندارد. تمام داده ها را در یک مجموعه داده بزرگ آموزشی جمع کرده و با مدل خود متناسب کنید.
با استفاده از مدل نهایی، می توانید:
- مدل را برای استفاده بعدی یا عملیاتی ذخیره کنید.
- مدل را بارگیری کنید و داده های جدید را پیش بینی کنید.
مرحله 2. مدل نهایی خود را ذخیره کنید
Keras با ارائه یک API به شما امکان می دهد مدل خود را در پرونده ذخیره کنید.
این مدل در قالب فایل HDF5 ذخیره می شود که به طور کارآمد آرایه های زیادی از اعداد را بر روی دیسک ذخیره می کند. باید تأیید کنید که کتابخانه h5py Python را نصب کرده اید. می توان آن را به صورت زیر نصب کرد:

می توانید با استفاده از تابع save () موجود در مدل، یک مدل مناسب Keras را ذخیره کنید تا فایل شود.
مثلا:
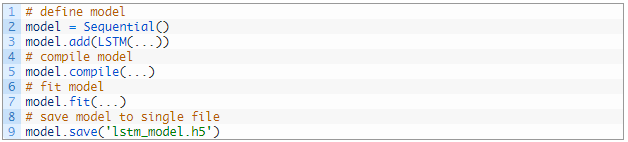
این فایل منفرد شامل معماری و وزن مدل خواهد بود. همچنین شامل مشخصات الگوریتم از دست دادن و بهینه سازی انتخاب شده است تا بتوانید آموزش را از سر بگیرید.
با استفاده از تابع load_model () می توان مجدداً مدل را بارگیری کرد (از یک اسکریپت دیگر در یک جلسه Python متفاوت).

در زیر یک مثال کامل از نصب یک مدل LSTM، ذخیره آن در یک پرونده و بعداً بارگیری مجدد آن آورده شده است. اگرچه بارگذاری مدل در همان اسکریپت است، اما این بخش ممکن است از اسکریپت دیگری در جلسه پایتون دیگر اجرا شود. با اجرای مثال، مدل در فایل lstm_model.h5 ذخیره می شود.
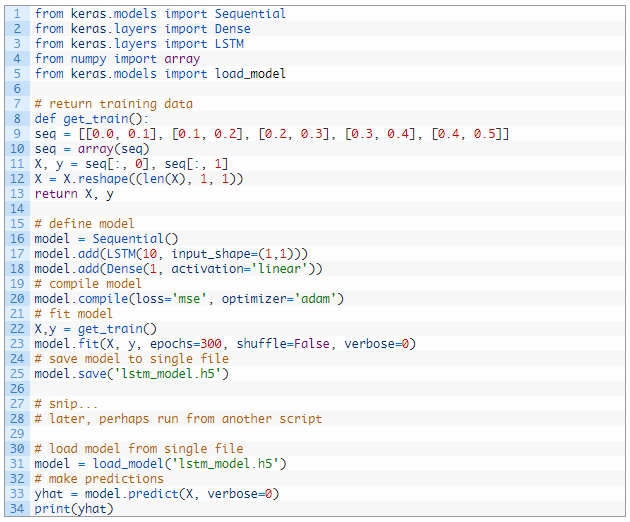
برای اطلاعات بیشتر در مورد ذخیره و بارگذاری مدل Keras خود، به پست مراجعه کنید:
مدلهای یادگیری عمیق Keras خود را ذخیره و بارگیری کنید
مرحله 3. پیش بینی داده های جدید را انجام دهید
پس از نهایی کردن مدل و ذخیره آن در پرونده، می توانید آن را بارگیری کرده و از آن برای پیش بینی استفاده کنید.
مثلا:
در مورد مسئله رگرسیون توالی، این ممکن است پیش بینی مقدار واقعی در مرحله بعدی باشد.
در مورد یک مسئله طبقه بندی توالی، این ممکن است یک نتیجه کلاس برای یک توالی ورودی داده شده باشد.
یا ممکن است هر نوع تغییر دیگری باشد که براساس مشخصات مشکل پیش بینی توالی شما باشد. شما می خواهید از مدل خود نتیجه بگیرید (yhat) با توجه به توالی ورودی (X) که نتیجه واقعی دنباله (y) در حال حاضر مشخص نیست.
شما ممکن است علاقه مند به پیش بینی در یک محیط تولید، به عنوان پشتیبان رابط کاربری، یا به صورت دستی باشید. این واقعاً به اهداف پروژه شما بستگی دارد.
هرگونه آماده سازی داده ای که قبل از تناسب در مدل نهایی شما بر روی داده های آموزشی شما انجام شده است، باید قبل از پیش بینی در مورد داده های جدید نیز اعمال شود.
پیش بینی قسمت ساده ای است.
این شامل گرفتن داده های ورودی آماده شده (X) و فراخوانی یکی از روش های پیش بینی Keras در مدل بارگذاری شده است.
به یاد داشته باشید که ورودی برای پیش بینی (X) فقط از داده های توالی ورودی مورد نیاز برای پیش بینی تشکیل شده است، نه همه داده های آموزش قبلی. در صورت پیش بینی مقدار بعدی در یک توالی، توالی ورودی 1 نمونه با تعداد ثابت مراحل زمانی و ویژگیهایی است که هنگام تعریف و متناسب کردن مدل خود استفاده می شود.
به عنوان مثال، می توان با فراخوانی تابع پیش بینی () در مدل، پیش بینی خام در شکل و مقیاس تابع فعال سازی لایه خروجی را ایجاد کرد:

پیش بینی یک شاخص کلاس را می توان با فراخوانی تابع predict_classes () بر روی مدل انجام داد.

پیش بینی احتمالات را می توان با فراخوانی تابع predict_proba () در مدل انجام داد.



مدیر سایت: بهزاد سرهادی کارشناس ارشد مهندسی آب
شناسه تلگرام مدیر سایت: SubBasin@
نشانی ایمیل: behzadsarhadi@gmail.com
(سوالات تخصصی را در گروه تلگرام ارسال کنید)
_______________________________________________________
پروژه تخصصی در لینکدین



 در منابع آب
در منابع آب


























نظرات (۰)